
La data open innovation ou l’art de collaborer avec d’autres organisations autour de la donnée. Un sujet dont nous verrons les contours et qui fait sens à l’heure de l’explosion des données. Nous verrons quelques exemples sur ce sujet d’avenir selon les experts avant de conclure sur une proposition sur la suite des travaux.
👉 J’aimerais en savoir plus sur la suite
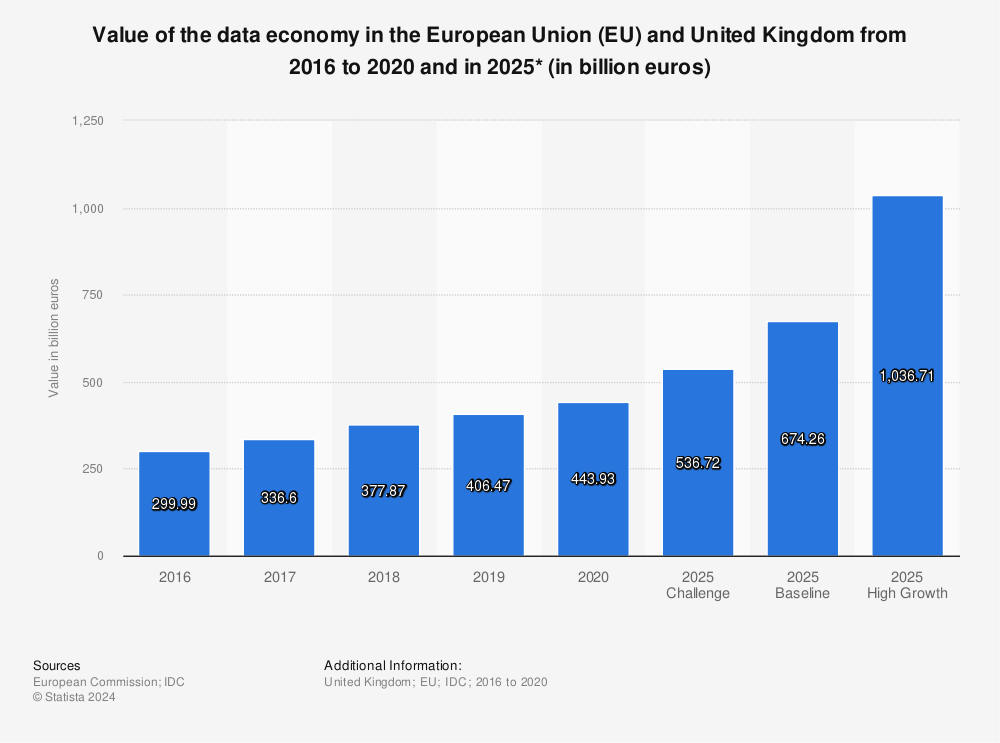
Nous utilisons Youtube, Facebook, Twitter, Google … Nos smartphones sont remplis d’applications. Certaines nous aident à trouver notre chemin, d’autres à prendre soin de notre santé. Sans même y prêter attention, derrière tous ces services il y a des données. Nous sommes loin d’en manquer. Le volume des data explose.

L’utilisation des réseaux sociaux – notamment le partage de vidéo – et l’envoi d’email augmente chaque année un peu plus ce volume de données (source : techjury.net). C’est, toutefois, la partie visible des données. D’autres data, stockées sur les serveurs des organisations, sont plus confidentielles. Des données qui ont moins l’habitude de circuler. Des données dont la valeur reste à découvrir.
La data : une route tracée pour des opportunités business
Parler de routes physiques pour un sujet aussi immatériel que les données peut surprendre. En même temps, connaissez-vous ce qui relie, entre autres, l’intelligence artificielle (IA), l’internet des objets (IOT), la Blockchain et le Metaverse ? Vous allez, peut-être, me répondre “des sujets tendances qui vont bousculer le monde dans lequel nous vivons”. Effectivement, “c’est pas faux”.

Ce lien, c’est la data. Les révolutions numériques que nous vivons et qui sont encore devant nous sont construites grâce aux données. De façon très schématique, l’IA se nourrit de données pour apprendre, l’IOT capte des données pour créer des services, la technologie Blockchain s’appuie sur une base de données partagée et certains Metaverse auront, peut-être, pour objectif de collecter plus de données pour un ciblage publicitaire encore plus précis – toute ressemblance avec Meta serait purement fortuite. Le potentiel de création de valeur est immense et les statistiques le prouvent.
Un rapport remis en 2018 par Henri Verdier – ambassadeur du numérique pour la France -, érigeait déjà certaines données au rang d’infrastructure essentielle. Notamment, le rapport mentionne l’article R. 321-5 du Code des relations du public et de l’administration listant 9 données de référence. Des données comme le Répertoire des entreprises et de leurs établissements ou encore le Répertoire opérationnel des métiers et des emplois (ROME). Des référentiels permettant de pouvoir regrouper différentes données sur les entreprises ou sur l’emploi grâce à une maille commune. Quand on y réfléchit, c’est plutôt pratique. Imaginez que chaque acteur travaillant sur les données entreprises ou lié à l’emploi travaille avec un référentiel différent. Comment rapprocher ensuite les données entre elles ? Ce serait bien compliqué. Ce type de données sont, selon le rapport, les routes du 21ème siècle. En dehors de ce cadre public, il y a probablement d’autres besoins liés à la standardisation des données nécessitant des échanges entre différents acteurs en mode open innovation.
Open innovation : un levier puissant
Qui n’a pas déjà entendu ce proverbe “seul, on va plus vite, ensemble, on va plus loin” ? Ce proverbe pourrait être la devise de l’open innovation, terme proposé par Henry Chesbrough, professeur à l’Université de Berkeley et diffusé grâce à son livre “Open Innovation : The New Imperative for Creating And Profiting from Technology” en 2003. Au cœur de l’idée, la collaboration, entre acteurs interne et externe d’une organisation, est une réponse positive à l’accélération du rythme des innovations. Autrement dit, pour éviter d’être has been accueillons à bras ouverts les idées des autres et inversement.
En pratique, deux courants s’opposent et parfois s’entremêlent. Un courant porté sur l’acquisition de connaissances externes dit “outside-in” composé, par exemple et sans être exhaustif, par l’achat de brevets, le rachat d’entreprises disposant de compétences ou de technologies stratégiques ou encore les communautés d’utilisateurs dont les retours sont toujours précieux. Un autre courant se concentre, lui, sur le partage de connaissances interne vers l’externe dit “inside-out” avec notamment, et là aussi sans être exhaustif, la mise à disposition de licence ou encore de données via l’open data.
Le point le plus intéressant, à mon sens, est le maillage de ces deux courants au travers de la création de groupe d’échange, d’écosystème permettant un partage mutuelle. Différentes appellations peuvent renvoyer à ces écosystèmes : alliances, consortium, open lab, hub …
La question est alors de savoir si de tels écosystèmes existent autour de la donnée.
Data open innovation mirage ou réalité ?
Imaginons le mariage de l’open innovation et de la data, cela donnerait-il la data open innovation ? Pas la peine de chercher cette expression dans votre moteur de recherche préféré, je l’ai déjà fait et je n’ai pas trouvé grand-chose. Ce mariage, porte-t-il un autre nom ? Si oui, je ne l’ai pas trouvé. Et comme le dirait un grand philosophe dont je tairais, le nom ici “si tu n’as pas trouvé, c’est que tu as mal cherché”. Possible. Si c’est le cas et que vous avez la réponse, n’hésitez pas à venir à ma rescousse en me contactant sur Linkedin ou sur Twitter. Plus sérieusement, pour répondre à la question mirage ou réalité, je vais partager avec vous mes premières trouvailles. Je pense, et je peux me tromper, que la data open innovation en tant que point de rencontre entre différentes organisations et différentes personnes a le potentiel pour faire émerger de nouveaux services grâce aux données. Les producteurs de données n’ont pas nécessairement la vision des usages possibles de leurs données. Et ceux qui auraient une vision ne sont pas nécessairement propriétaire de données. Ces rencontres peuvent aboutir, par exemple, à l’identification de standard, de protocole d’échange, de partage de données dans un cercle fermé voir public en open data. J’ai mené des premières recherches que je vous partage.
Première trouvaille, extrêmement intéressante, l’existence de l’open data institute (ODI). Une organisation à but non lucratif créée en 2012 et basée à Londres par Nigel Shadbolt et Tim Berners-Lee. Le nom de Tim – osons la proximité – vous dira probablement quelque chose. C’est l’inventeur du web. Et l’ODI a construit une représentation très instructive appelée le data spectrum.

Dans cette représentation, il est intéressant de noter la présence de flèches qui indiquent un mouvement de gauche à droite et de droite à gauche. Ce mouvement, montre pour moi, une évolution possible des données fermées, aux données partagées voire aux données ouvertes à tous. Ce n’est pas complètement étanche et cela peut évoluer dans le temps.
D’ailleurs, autre trouvaille passionnante, un programme de travail s’est penché sur le partage des données notamment fermées et a rédigé le “Data Sharing Toolkit”, la boîte à outils du partage de données. Je vous invite à regarder ce document listé dans les sources de cet article et dont j’ai adapté une représentation illustrant quelques points d’attentions.

Pour terminer cette partie sur la data open innovation mirage ou réalité, j’ai mené un travail de recensement. Celui-ci n’est pas exhaustif. Il a, toutefois, le mérite de montrer que plusieurs initiatives ont démarré autour de collectif, autour de données, pour créer de la valeur.
Le consortium Melloddy, créé en 2020, prend soin de créer des médicaments grâce à des algorithmes de machine learning appliqués à des données mises en commun par ses membres. Une partie des travaux sont privés et une partie est disponible en open data sur Github.
Le Health Data Hub, créé en France fin 2019, fédère 56 partenaires du secteur public et privé autour de la donnée de santé. L’organisation prescrit 4 axes stratégiques : mettre en valeur le patrimoine de données, faciliter l’usage des données, protéger les données des citoyens et innover avec l’ensemble des acteurs. Le partage de données entre les membres et en open data est inscrit dans la démarche.
Le consortium Space Data Marketplace, mis en orbite fin 2021 dans le cadre du plan spatial France Relance, vise à faciliter la circulation des données spatiales au niveau européen, avec un atterrissage autour de cas d’usage, entre autres, sur la mobilité, les infrastructures et l’environnement. Les données sont monétisées sur une plateforme commune encadrée par une gouvernance de confiance.
Ekitia (ex-Occitanie Data), association créée en janvier 2019 en cours de transformation en un GIP, rassemble une soixantaine de membres publics et privés et œuvre à développer l’économie de la donnée dans un cadre de confiance, éthique et souverain. Les entreprises qui la composent sont parfois concurrentes (coopétition).
L’Open Ag Data Alliance, dont la première graine a été plantée aux Etats-Unis en 2014, fertilise le partage de données grâce notamment à la standardisation de protocoles d’échange.
Num-Alim, Société Coopérative d’Intérêt Collectif, alimente une base de données grâce à l’implication d’une quarantaine de membres associations ou entreprises. Montée en qualité et valorisation sont les ingrédients de la plateforme de partage de données agro-alimentaire.
Île-de-France Smart Services, est un chantier lancé par la Région Ile de France depuis fin 2019 autour de l’idée d’un smart territoires, vision étendue du concept de ville intelligente ou smart city en anglais. L’objectif est de construire des services grâce aux données apportées par les acteurs publics et privés. Le club partenaire affiche plus de 150 membres et une ambition autour d’un partage entre partenaires et également en open data.
La Data open innovation a-t-elle vraiment un avenir ?
Pour répondre à cette question, je vais laisser la place à trois experts : Mick Levy, Laurence Joly et Sea Matilda Bez.

La Data Open Innovation est le prochain palier de maturité des entreprises data-driven. Bien plus qu’un sujet d’avenir, elle va permettre l’avènement des entreprises plateformes. Ces entreprises hyper agiles, savent non seulement créer de la valeur avec leur patrimoine de données, mais aussi par l’échange de données avec des partenaires, des autres organismes publics ou privés, l’open data, etc.
C’est ainsi que la mise en commun de données va permettre les concepts de federated learning et d’inventer des usages dans lesquels plusieurs organisations créeront de la valeur et de nouvelles sources de revenus.
Ce thème est d’ailleurs mis en lumière dans les 7 sujets chauds Data IA repérés par Business & Decision pour 2022.
Mick LEVY – Directeur Innovation Business chez Business & Decision

La place accordée aux données et à leur valorisation dans la stratégie d’une organisation est sans doute un des critères les plus explicites pour juger du degré de transformation numérique.
L’intégration de données externes et le partage des données structurées produites en interne est une stratégie rarement évoquée par les entreprises. Pourtant, les données représentent des actifs immatériels et peuvent faire l’objet d’une valorisation au même titre qu’une technologie ou un savoir-faire : ces données peuvent être vendues (avec toutes les limites liées aux données personnelles) mais aussi partagées dans une démarche d’open innovation.
Paradoxalement, les acteurs publics sont en avance sur le sujet grâce aux injonctions à l’open data et la mise en place de grands projets inter-administrations durant la dernière décennie.
On peut espérer que le développement d’initiatives public-privé de data open innovation permettra une prise de conscience au sein des entreprises que le partage de données peut permettre de créer de la valeur.
Laurence JOLY – CEO – Diag n’Grow

Les données ont été étiquetées comme le “nouveau pétrole”. Mais ce n’est pas le pétrole en lui-même qui crée de la valeur, mais la façon dont nous l’utilisons pour faire fonctionner les machines. Idem pour les données, ce n’est pas seulement d’avoir des données qui compte, mais comment utiliser les données.
Ce que j’aime avec le concept de Data Open Innovation, c’est qu’il met l’accent sur l’idée de partager délibérément des données avec des acteurs externes pour débloquer et accélérer l’innovation. Et comme l’explique David dans ce post, on peut “outside-in des données” (utiliser des données d’acteurs externes pour innover) ou “inside-out des données” (laisser d’autres à extérieur de l’entreprise innover avec nos propres données et obtenir quelque chose en retour en cas de succès).
Personnellement, je vois aussi deux nouvelles tendances pour le Data Open Innovation : Inside-in et Outside-out Data Open-Innovation.
Le “Inside-in Data Open Innovation” se concentre sur les frontières internes de l’entreprise. Les grandes entreprises ont tendance à travailler en silos, et avant même de penser à innover avec les données en externes, pourquoi ne pas se concentrer sur le partage et l’utilisation des données internes entre les business units pour favoriser l’innovation ? Thuy Seran et moi même, avons identifié un début de réponse (i.e « Multiunit Back-End Problem » ou “coopétition interne”) Non gérée, la compétition perçue entre les business units peut freiner toutes collaborations et utilisation internes sur les données et donc freiner l’innovation de l’entreprise.
Le Outside-out Data Open Innovation se concentre sur l’orchestration du partage des données d’un écosystème (c’est-à-dire entre des acteurs extérieurs à l’entreprise). David donne plusieurs exemples dans ce post.
Le vrai enjeu de demain est de savoir quand, pourquoi et comment mettre en œuvre inside-in et outside-out data Open Innovation. Les premières entreprises à saisir ces défis auront “le first mover advantage”.
Sea Matilda BEZ – Maître de conférence à Université de Montpellier – spécialiste de Open-Innovation
Pour conclure cet article, la data open innovation est un sujet d’avenir avec des exemples au présent. Un sujet intéressant à suivre avec un fort potentiel économique et de nombreuses applications (intelligence artificielle, internet des objets, standardisation…).
Si le sujet vous intéresse également, je vous invite à me le faire savoir en renseignant ce court questionnaire pour recevoir mes prochains articles et/ou pour contribuer à la réflexion.
👉 Je souhaite recevoir ou contribuer aux prochains articles/travaux de David
Sources :
Statista : Le big bang du big data
Statista : Value of the data economy
Techjury : How much data is created every day
Etalab : Rapport « La donnée comme infrastructure essentielle »
Datapitch : Data sharing toolkit




![[Masterclass] Emmanuelle FLAHAUT-FRANC – Into the FRENCH TECH : décrypter l’écosystème STARTUP](https://mbamci.com/wp-content/uploads/2023/11/masterclass-MBAMCI-500x383.jpg)
